The Challenges of Distributing Your AI App
7 January 2025
These problems are impossible to ignore

With modern development tools, one can quickly create the functional MVP of an application. Aren’t AI-enhanced ideas the perfect candidates for such experiments? However, the dependency on AI represents challenges that cannot be overlooked, as they can quickly swamp a simple project.
I originally envisioned my game JOBifAI as a weekend project to serve as a proof of concept for what a ‘social persuasion’ game can be. It’s one of the main features of AI, and I’m glad to see that there are other implementations of it. This tests verbal skills in ways that were not possible before; parser based approaches feel rudimentary compared to it.
This gave JOBifAI a very limited scope, focusing specifically on highlighting that aspect within a 15-minute experience. However, the unique challenges of integrating AI forced us to consider more issues than we initially planned, extending the timeline to over a month, along with additional delays caused by the platform.
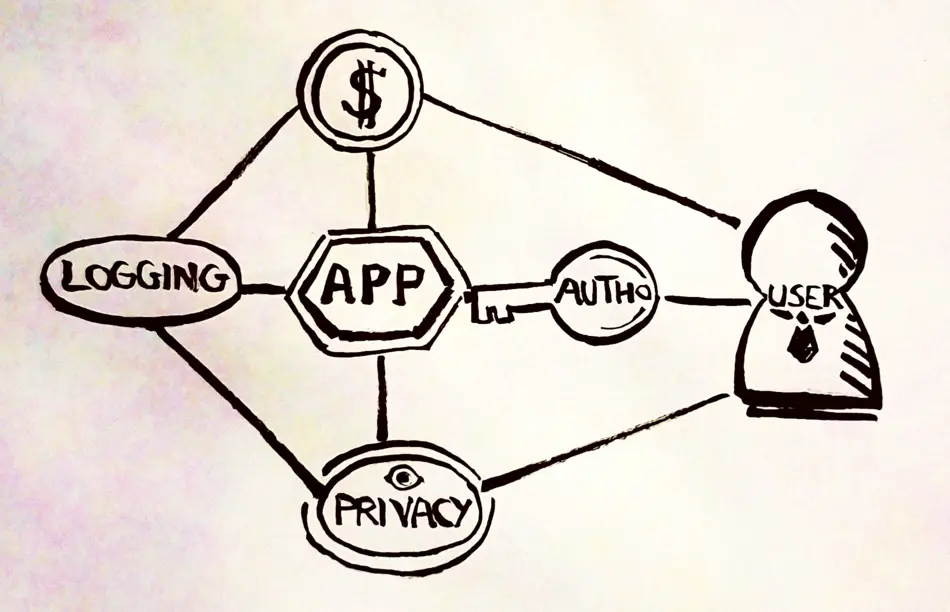
This is before even really considering the inherent challenges that come with developing LLMs:
- it’s truly non-deterministic
- switching between models can be costly, as the same prompt may produce completely different results
- specific application requirements may require to change service, which may not be compatible with the same API
Polishing the user experience may thus take much more time than expected. The retry mechanism for LLM queries needs to be quite elaborate, but its functionality is limited to be janky anyway.
The issues above will quickly come up during development, and you may look at this previous post for more details. However, distribution introduces a whole new set of questions. Should your app work offline? How to work with privacy concerns? What about costs and pricing models? These are questions that you want to ignore while focusing on the core experience, but cannot really avoid if it uses AI. We’ll see why with concrete examples, so let’s explore them in detail.
framework and distribution constraints
There are essentially two requirements, that appear very basic:
- make HTTPS requests
- be able to store files on disk
The second one could be alleviated by saving files to another system that can be accessed via a simple url, at the price of higher infrastructure complexity and higher monetary cost.
While these are very basic, the constraints we had for the application shortlisted a few options which did not satisfy both constraints.
Simply distributing an executable is more difficult than it should be; our first MacOS beta tester had trouble bypassing security constraints and was unable to authorize the app to save files. Giving instructions to bypass multiple security warnings, which indicated that our program could harm the user’s computer, did not seem very appealing.
The other obvious choice, is to target an HTML5 build. However, Ren’Py does not support HTTPS requests in HTML5 builds. Being able to save large files severely limits what can be done in the browser, which restricts a website’s local storage to 20 MB. Since each playthrough requires about 3 MB of images, this is a significant concern.
Given the multiple restrictions we faced, we chose to distribute on Steam — the easiest solution with its hassle-free 1-click install for end-users. Steam has a registration fee, week-long delays for any queries, and guidelines for AI content that are not yet well-defined. Our first build was rejected for reasons that essentially fell outside the established rules, but it depends on a more subtle understanding of both our implementation and the rules.
always online or face tedious installations?
This one is obvious, but most systems have stringent requirements that essentially make it unreasonable to perform inference locally. The space requirement, and in most cases the compute requirement, make it prohibitive to run on consumer device. This is especially the case when running advanced AI systems concurrently (such as LLMs and image generators).
Because of this, the application has to consider authentication to make calls through an intermediary server.

privacy and safety concerns
Both are in the same category because despite being completely different, they are at odds with each other. There are two aspects to the safety issue:
- unsafe queries might repeatedly fail and incur a higher cost. Logging is necessary to be able to detect it.
- unsafe result might be a problem for end-users. To prevent such issues from happening again, logging is necessary to get the full context. This may also help protect against abusive reports (used as outrage-bait against the program), by providing full context that shows whether a user was, in fact, trying to achieve the unsafe result.
Of course, logging everything might be expensive, and could raise serious concerns in the event of cyber-attacks, as a data breach might expose sensitive information.
To workaround this, one simple solution is to use a unique identifier, ensuring that the logging process remains free of any user data. In our case, we used an identifier provided by Steam, and the authentication part of the application just passes a unique identifier, allowing us to aggregate useful data without the risk of linking it to personally identifiable information.
pricing (and cost)
Most AI services run on a usage-based model, plus a base subscription price. This essentially rules out the one-time purchase as a viable model. Furthermore, this imposes a hard constraint on the application’s pricing model, which can take one of two possible forms:
- pay-per-use: charges users based on their actual usage of the application, which may limit the application’s profit margins
- subscription: the risk is that users must expect constant and long-term value to commit
This creates a significant barrier to initial usage. To bypass that, the option is to provide a free demo, which lowers the initial barrier to user authentication. This can be made easier with Single Sign-On (SSO).
However, this means that the application should also be able to support the cost associated with the free trial, which may be orders of magnitude higher than those for paying customers. Free trials also need to be long enough to be meaningful, but not so long that they satisfy all the needs of a would-be customer.
This is a very delicate balancing act to successfully find a point of equilibrium.
So should you face the music?
It isn’t surprising that AI can kill many ideas. So many constraints, competitors benefiting from unsustainable pricing due to investor funding, and a user experience that may be subpar because of forced jankiness.
Our experiment made it to Steam, and it was a great learning experience. It was satisfying to see so many people who ‘got it’ — almost one-third of players got all the achievements! However, it also serves as a cautionary tale about the issues of relying on AI (a very meta lesson from JOBifAI!).