the medium and the message and the humans
6 June 2023
A metapost about learning to write (technical?) content.

When Stable Diffusion came up in online discussions I thought about a specific take that I could not see anywhere and would not fit into a comment, which made me start this blog. I didn’t have any real plan for its content; since other things at the intersection of artistic activities and computing came up, that became the main subject for the following posts.
I didn’t have much experience with writing, and I still don’t. Style, clarity and brevity need work, but as I learnt this is only a fraction of the time spent1. So, what takes the most time?[^math]
linearizing the knowledge graph
Writing is a perfect fit for storytelling, since this is a linear process that excels when managing in unison the reader’s emotions and the narrative flow. For technical subjects, there is very little emotional content, and the ideas tend to organize themselves in a complex graph.
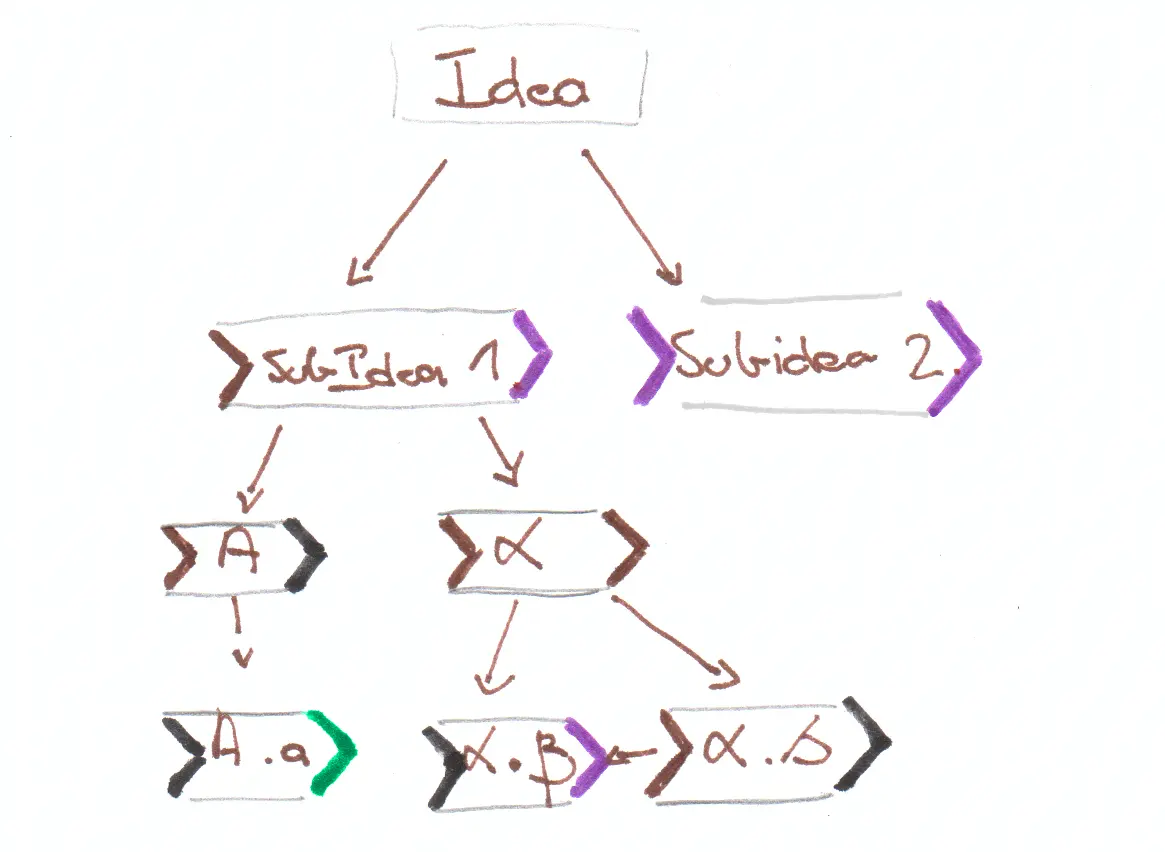
In this case, the colors indicate a category of arguments; matching colors mean one idea flows naturally into the other, while arrows show strong logical dependencies between ideas (that may belong to different categorical domains). When linearizing this graph, there are a number of difficult choices to make. For example, do you cover point \(A.a\)? It is not connected to anything else so it’s the only place to do it, but doing so strongly breaks the flow because of its unique category. You could also decide to cover \(\alpha.\delta\) before \(\alpha.\beta\), knowing that it makes for good transitions but at the cost of inverting the order of the ideas.
To manage this, I tend to start writing individual blocks of text, and then try to organize them in a coherent way. Moving them means that their content should be reworked to fit the new context, in terms of transitions, length, and what terms have already been covered. However after a certain time fatigue sets in and it becomes easy to overlook inconsistencies introduced when moving blocks around. Pacing and writing themselves are made significantly harder by this process.
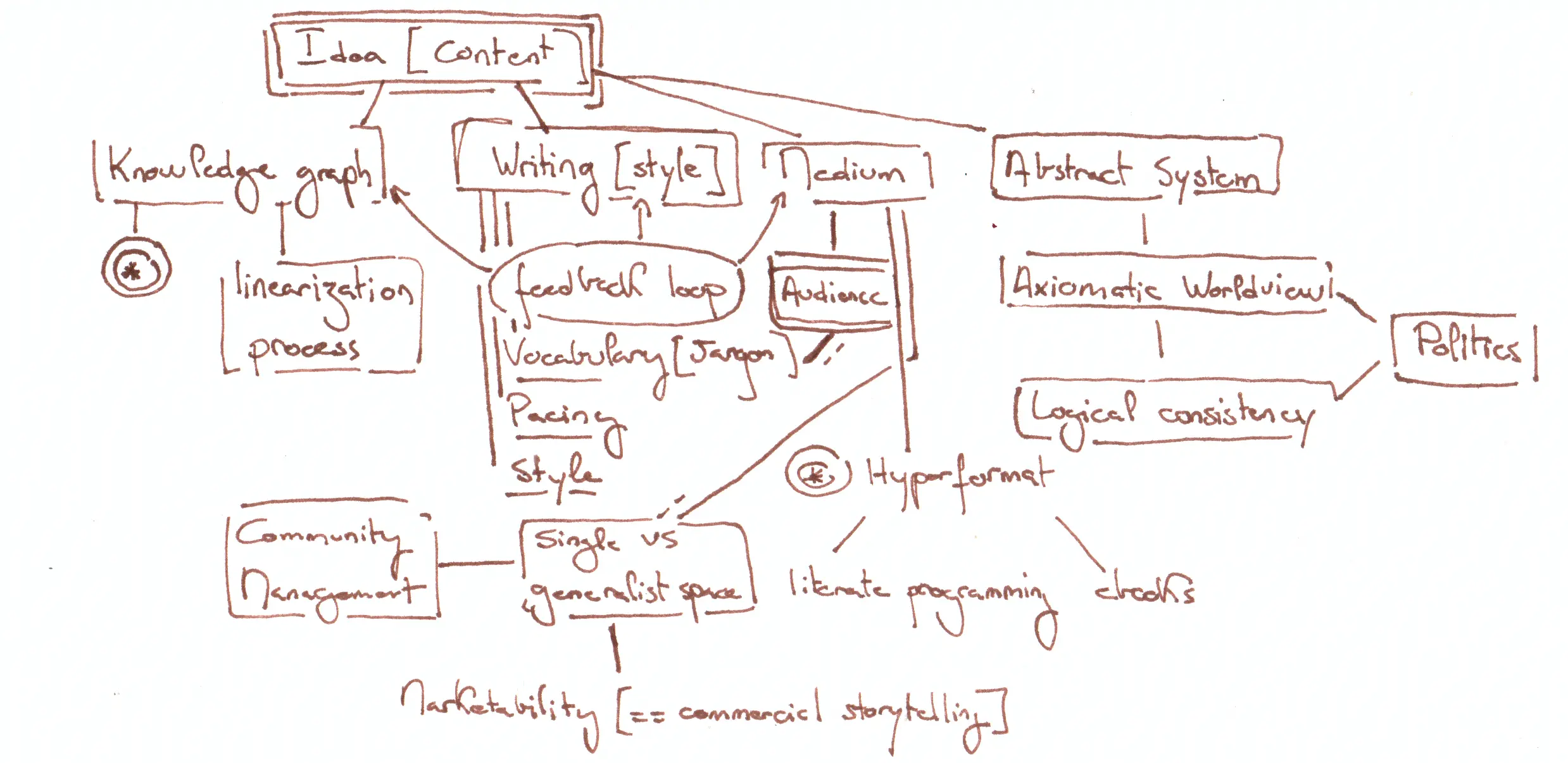
Here is the knowledge graph for this blogpost. Note that this is also just one arbitrary choice in how it is visually displayed.
In this light, writing becomes an optimization problem over possible linearizations. Another way could be to avoid this step altogether…
non-linear formats
One thing that felt fresh and interesting 2 decades ago was the idea of hyperlinks. Any word can link to its definition, or to a related concept, a related blogpost. This way you naturally convey your own worldview in a synthetic way. However after a certain time this becomes exhausting, and this style has largely gone out of fashion since then. It’s a natural form of the knowledge graph, yet this representation is only implicit, as are the nature of the relationships; it is a graph, but lacking structure.
Considering learning a mathematical subject, there are different paths one can take. Problem-based, definition based, top-down or bottom-up. Parts of that learning process could be cut up into different units, and each learning approach chosen as a learning path. During the release of the Kindle, it was the direction I hoped ebook would tend to. However I’m not aware of even one attempt at doing this.
It’s not too unlike literate programming. Literate programming is the idea that the program itself should be compiled from a document that explains the program. So a compiled file could be scattered in multiple points of the document, where it most makes sense to explain it. (The idea is mostly confused with ‘documented code’, where ‘fn: do_smthg’ is often documented by ‘this function does something’, a tautological waste of characters).
These ideas never caught on, and probably never will.
It seems also linked to the long-term dominance of standard formats. Beyond the power of plain-text, I suspect these ideas that rely on a structural compilation step are doomed to fail without another genius idea. Editing a non-linear format requires good tooling, a lot more encoding, and has a much higher complexity because of all the possible outputs. Delving into these reasons could make for an interesting topic.Another interesting approach to mention, although not as radical, is Tufte’s use of side notes and margin notes. With an hyperformat you can also show and hide subelements on demand, and adapt the presentation to different device formats.
detail level
For each idea, you need to decide how detailed you want the section to be. The main issue being that most of the sentence will need to be rewritten entirely depending on the detail level. And because it has an impact on the pacing of the overall piece, it may be necessary to change that at a late stage. If we refer back to the knowledge graph, we would be selectively pruning some branches. The main deciding factor would be who the audience is.
(meta) content organisation, or the audience

In general specialized content wins over general space. It is easier this way to find information by restricting the focus to a specific subject. This is also an easier thing to market and brand, as it defines a target audience. But there are also issues arising from this. In a way any ‘sub-community’ is distinct by having its specific values, so engaging with it skews one’s own value system. As a result, there is a high risk of purity spirals – a concept quite related to ‘echo chambers’, in an extended sense.
the medium shapes the humans
This is something that can be observed at the micro and macro level. For the micro-level, consider how the way a sentence is phrased can change the way it is perceived. At any point, new information changes the frame of mind of the person who receives it. At the macro level, the printing press, the internet changed society as a whole because it disrupted the existing information flow sufficiently that it threw off the existing power balance. Furthermore, humans tend to quickly adapt to a ‘new normal’ and naturally reproduce it.
It is also an interesting thing to consider when evaluating the impact of, for example, social media platforms. Even if people escape Twitter, they can hardly escape the change it has made to their way of thinking. This made me think of McLuhan’s ideas in a way that I hadn’t considered before. I suspect it was more apparent because the impact of social media represented a notable change that I directly experienced whereas I hadn’t known life before television, his own main study subject. It seemed to be a very ‘philosophical’ concept, whereas now it seems to be a very practical matter that cannot be ignored.
Because of this inevitable feedback loop, any knowledge produced by a human is dependent on the previous ideas they have been exposed to.
abstract ideas; everything is political in a post-truth era
A direct consequence is that ‘objective’ knowledge is impossible to attain; the original sin is called ‘bias’. With a new worldview acknowledging the diversity of viewpoints and life experiences, truth has to accommodate a diversity of new, incompatible perspectives, that are all equally valid. This framework of cultural critique destroyed the basis of the previous worldview but failed to produce any logically consistent system to replace it. Because of this, language has been reduced to some Wittgenstein-ian game centered around power struggle and human persuasion. Political battle lines are nowhere and everywhere, consistently with the evolution of the meaning of “political”.
The consequences of this illogical power structure cannot be escaped, questioning the whole point of any thinking at all when (political) might is right. Yet people are existentially searching for meaning, so the need to think remains, despite the risks.
going forward
I’m not sure that writing lets one achieve greater clarity of thought. Unsatisfaction with this post means that I’ve worked on it for more than 2 months, but I don’t feel like my thoughts are any clearer than they were. After a number of different writing activities (including a novella I will cover in another post) this seems to me to be an almost entirely different activity, as different as would be debating or poetry, even though there are similarities in how language is used. In the search for answers, it is interesting to persevere to see where that leads.
appendix: mathematical digression on the optimization problem
(This section couldn’t be hidden in a detail tag because of the \(\LaTeX\) script.)
If we wanted to formalize that, take \(G=(V, E, I, O)\) to be a graph provided with \(I, O\) being both functions \(V \rightarrow \Sigma\), where \(\Sigma\) is an arbitrary alphabet (say the categories of ideas that are under scrutiny). The vertex set \(V\) is the set of ideas we want to address in the final text, and \(E: V \times V \rightarrow [0, 1]\) indicating the strength of a link between ideas. Then the problem is to find a bijection \(f: [\mathbb{N}] \rightarrow V\) that maximizes \(\sum_i w(f(i), f(i+1))\) for some weight function \(w\). Of course \(w\) should depend on both \(E,I,O\), but given these constraints any choice could be made. The weighting could put a strong penalty on ignoring direct dependencies, or a strong penalty on ignoring the categorical flow, etc.
For completeness, this is the problem that this linearization solves, but I’m not formally encoding it. In particular, the ‘best’ linearization depend strongly on the cost function \(w\). Getting the best linearization for a set of natural metrics, would help deciding on a given order but there is such a high cost to encode everything that it probably would not be worth the effort. In any case it is a problem where the ultimate decision is human and a function of taste, so it would be limited to be an informative tool. Getting to understand what the metrics mean with respect to human understanding would also be a research project in and of itself. Furthermore, I believe this is an idea that belongs to the class of “interesting concept but will never be practically used”.
Note also that the graph is also quite a simplification of the problem since it’s ignoring the difference in the hierarchical level of different nodes as well as the importance of the different links between them. It’s even unclear if adding that level of detail would make such a representation more useful.
-
Or let’s just say I have very low standards for writing quality. ↩